
Jupyter Notebook
To launch a Jupyter Notebook on https://hpc.grit.ucsb.edu select Interactive apps from the top menu bar and select Jupyter Notebook from the dropdown.
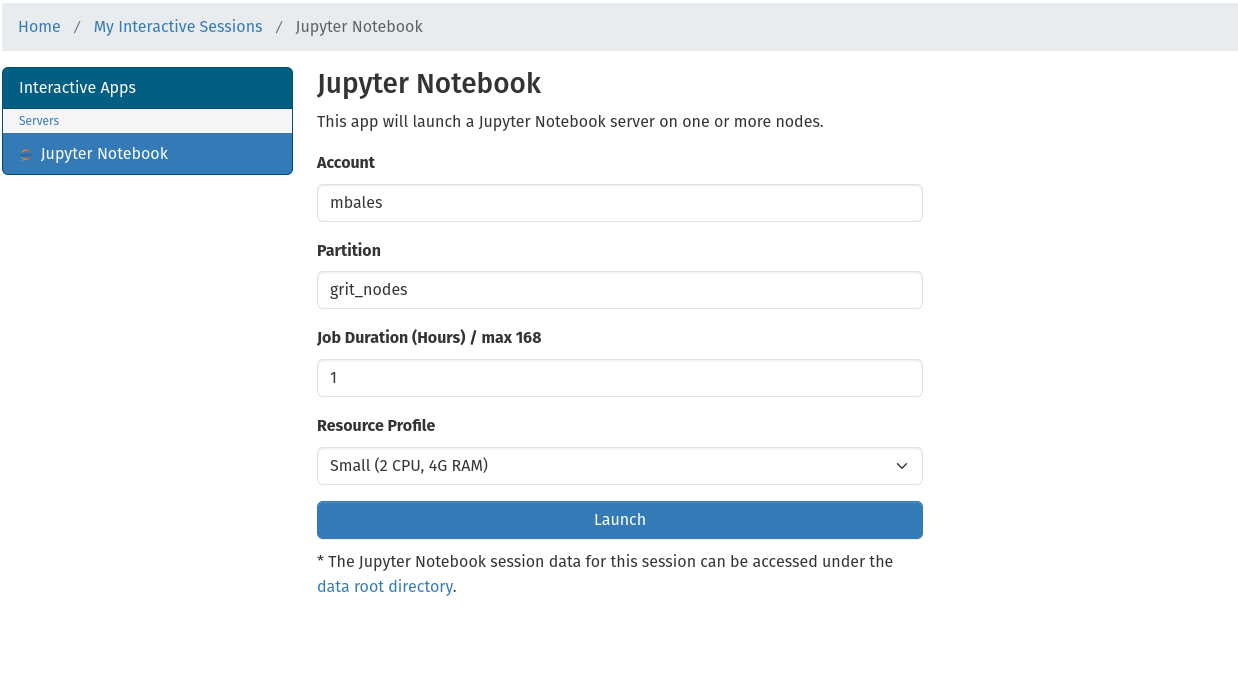
Once in the Jupyter Notebook spawner page you will need to fill in the following fields:
- Account: your SLURM account, this will be slurm_users by default, or slurm_labname for those with private resources
- Partition: grit_nodes is the default
- Job Duration: set a number of hours for your Jupyter Notebook to run, after this expires your job will be stopped.
- CPUs: set the number of CPU cores to be allotted for this task, with a maximum of 24. (this maximum is selected so as to not consume 100% of the cores on any of the HPC systems in the GRIT stack)
- RAM: set the amount of RAM in gigabytes available to this task, with a maximum of 256GB. (this maximum is selected so as to not consume 100% of the RAM on any of the HPC systems in the GRIT stack)
- Job Name: this field is optional and may be used to differentiate tasks if multiple are running under the same account.
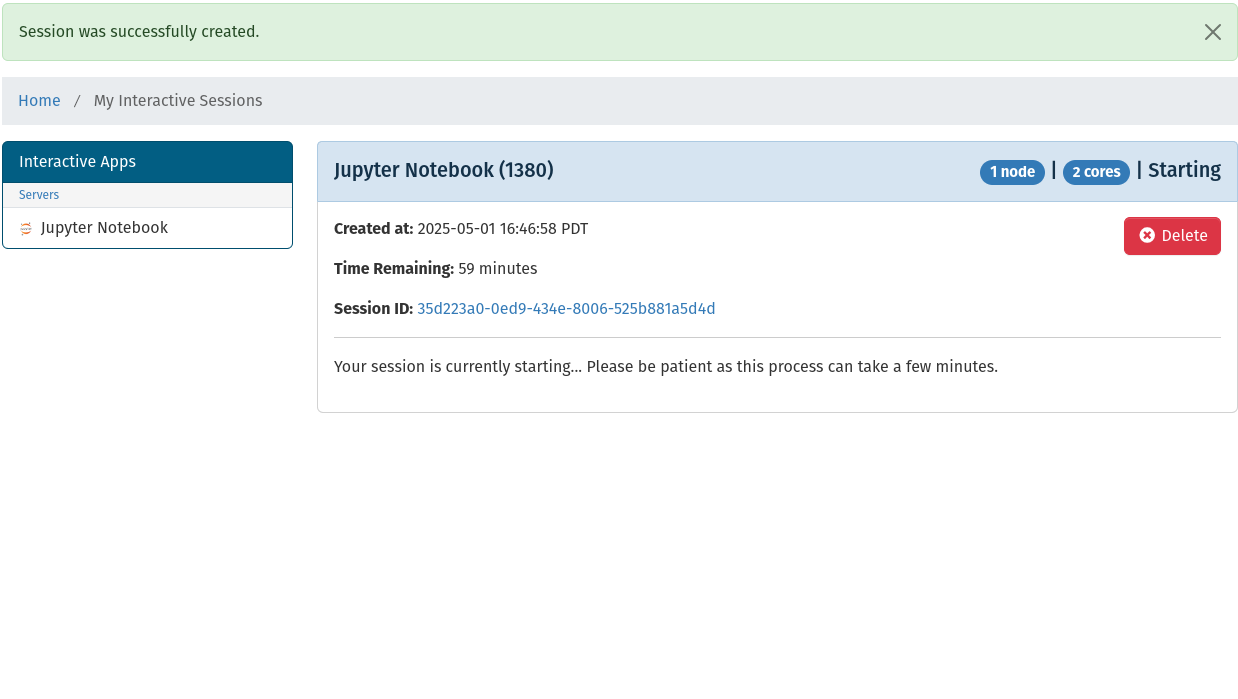
Once those fields are completed select the launch button. This will return you to the My Interactive Sessions page and show the currently spawned job as well as any past jobs that have been completed. It will take a few seconds for the job to launch as long as there is available resources on an HPC host. If there are not enough free resources on any host the job will time out after 1 minute:
If the job spawns successfully the session window will update with a Connect to Jupyter button, a host button, and a delete button:
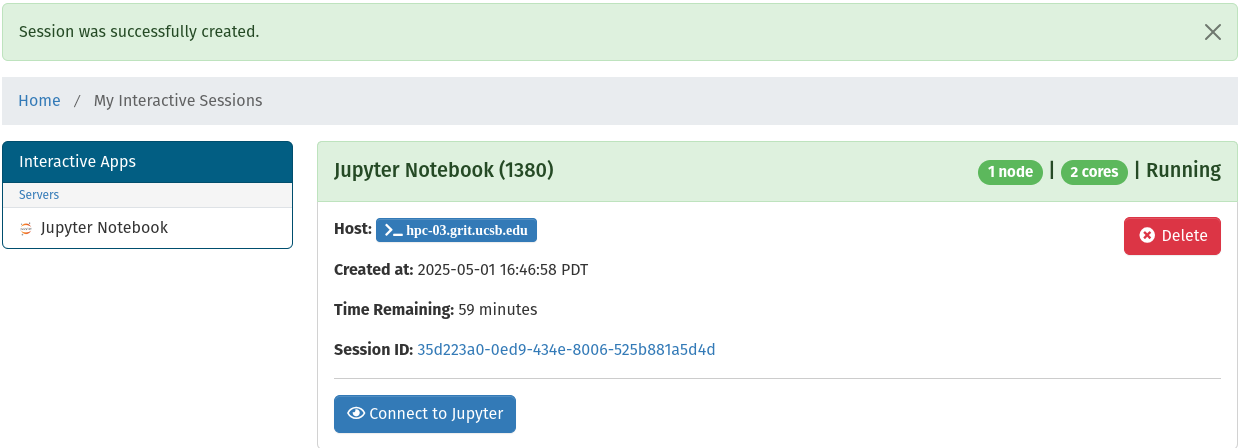
- The Connect to Jupyter button will take you to your Jupyter Notebook
- The Host button will take you to a terminal session on the HPC host your job is running on
- The Cancel button will immediately close your Jupyter Notebook session
- And the Delete button will delete the session card from the list
Tips and Tricks:
If you run code in a notebook that only outputs to the notebook and then leave the page the code will continue running, however the output will not be captured. If you want to capture the output and not have to leave the page open you must write the output to a file.
Known Issues:
Jupyterhub's built in file browser is not able to navigate file directories outside of the user home folders. The easiest work around is to enter the full directory path which can be found either via the CLI or OOD File browser. It is also possible to add symlinks to your home folder for arbitrary directories but this is not advised unintended as it can have adverse effects on your home folder.
Due to the number of groups we support and their unique requirements we do not currently set a default shell in the jupyterhub terminal. This means you will be dropped to /usr/bin/sh by default and none of your bashrc / cshrc / zshrc settings will be applied. To resolve this simply type your preferred bash at the $ prompt and press enter. We currently support:
- zsh
- bash
- tcsh